Algoritmia de IA – Pandas y LogisticRegression

Vamos a explorar el manejo de una biblioteca muy utilizada en el tratamiento de datos para Algoritmia de IA.
Pandas
Pandas es una librería de Python especializada en la manipulación y el análisis de datos. Ofrece estructuras de datos y operaciones para manipular tablas numéricas y series temporales, es como el Excel de Python.
Tal como siempre recomiendo a mis estudiantes: «No olvidar Leer la documentación Oficial». Pandas Oficial
Objetivo
Desarrollar un Algoritmo que pueda predecir el porcentaje de probabilidad de aprobar y desaprobar el curso un nuevo estudiante basándose en su edad y en los datos históricos de 500 estudiantes anteriores y sus evaluaciones t1,t2,t3 y t4.
Recursos para este ejercicio:
- Tener instalado Jupyter Lab o Google Colab
PASO 1
Importar Set de datos

PASO 2
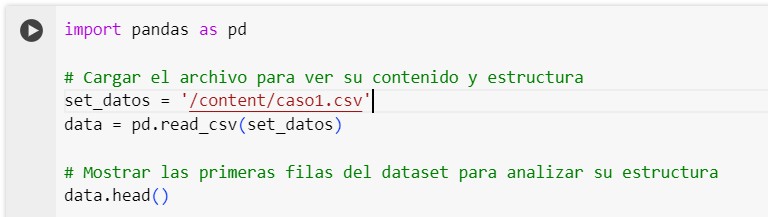
Vamos a importar Pandas para el tratamiento de los datos. Luego creamos una variable con el nombre set_datos para recibir el csv y luego poder darle tratamiento mediante el metodo pd.read_csv de Pandas. Su función es leer datos de un archivo CSV (Comma Separated Values) y crear un DataFrame de Pandas con ellos.
Luego, mediante el método head(), también de Pandas, mostramos los primeros registros del DataFrame.
El código:
import pandas as pd
# Cargar el archivo para ver su contenido y estructura
set_datos = '/content/caso1.csv'
data = pd.read_csv(set_datos)
# Mostrar las primeras filas del dataset para analizar su estructura
data.head()PASO 3
Notamos que el CSV está delimitado con «;» por ello vamos a darle tratamiento con este delimitador.

El código:
# Cargar nuevamente el archivo con el delimitador correcto
data = pd.read_csv(set_datos, delimiter=';')
# Mostrar las primeras filas del dataset para verificar la estructura
data.head()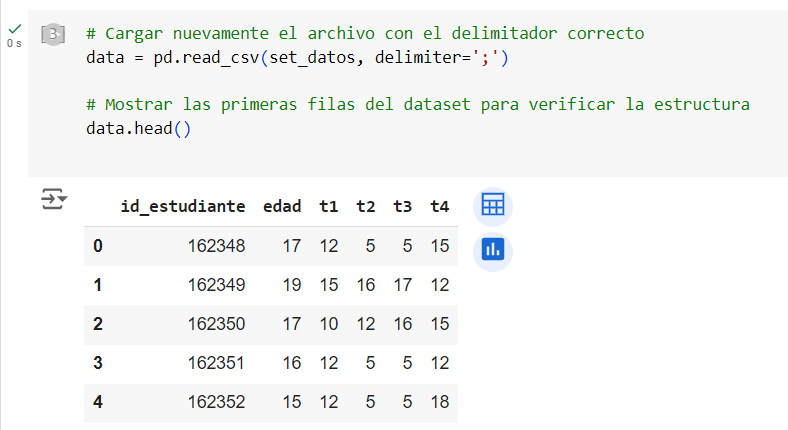
PASO 4
Vamos a generar una columna llamada promedio donde recibiremos todos los promedios de todos los estudiantes línea por línea con base en las evaluaciones t1,t2,t3 y t4. y ordenaremos un poco los registros.
Para calcular el promedio usaremos el método mean() de Pandas.
Axis especifica la dimensión a lo largo de la cual se realiza la operación, puede tomar 2 valores: 0 y 1. Si es 0 el tratamiento será vertical y si es 1 el tratamiento es horizontal.
Para nuestro ejercicio, como los promedios están dados de forma horizontal, colocaremos axis=1
Líneas abajo creamos una variable llamada data_ordenada donde recibiremos el DataFrame ordenado mediante el método sort_values de Pandas y su argumento ascending.
Finalmente, presentamos los datos con el método to_string()

Recuerda ir apuntando estos métodos y argumentos en algún bloc de notas para que lo tengas a mano en futuros proyectos.
El código:
data['promedio'] = data[['t1', 't2', 't3', 't4']].mean(axis=1)
print(data[['id_estudiante', 'edad', 'promedio']])
data_ordenada = data.sort_values(by=['edad'], ascending=True)
print(data_ordenada)
print(data.to_string())PASO 5
Ahora vamos a presentar los datos mediante una gráfica usando la biblioteca Matplotlib.
Importamos la librería, luego creamos una variable llamada edad_promedio para trabajarla con matplotlib. Con el método groupby() de Pandas y pasamos los promedios mediante mean()
Empezamos a dibujar la gráfica con el método figure() de matplotlib y le establecemos un tamaño de 10×6 pulgadas con el argumento figsize.
Con el método bar() de matplotlib dibujaremos una gráfica de barras pasándole los argumentos bidimensionales. Notar que tenemos los datos en la variable edad_promedio. Podemos usar otra gráfica de matplotlib a criterio, se recomienda leer la documentación de Matplotlib.
Finalmente colocamos las etiquetas: Título, Edad, Promedio de Nota y pasamos las edades al eje x mediante xticks(), el cual es un método de Matplotlib.
Si deseas puedes agregar una cuadrícula a la gráfica para facilitar su lectura mediante el método grid().
Finalmente, presentamos con plt.show(), su explicación es más que obvia.

El código:
import matplotlib.pyplot as plt
# Agrupar por edad y calcular el promedio de la nota
edad_promedio = data.groupby('edad')['promedio'].mean()
# Crear el gráfico de barras
plt.figure(figsize=(10, 6))
plt.bar(edad_promedio.index, edad_promedio.values)
plt.title('Tendencia de la nota en base a la edad')
plt.xlabel('Edad')
plt.ylabel('Promedio de la nota')
plt.xticks(edad_promedio.index) # Mostrar todas las edades en el eje x
plt.grid(axis='y') # Agregar una cuadrícula al eje y
plt.show()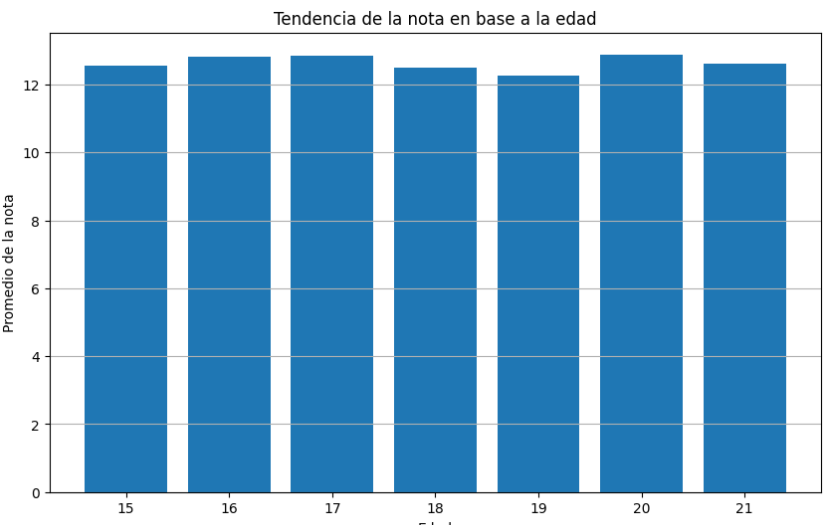
PASO 6
Ahora vamos a crear una columna llamada “aprobado” para almacenar 2 valores [0 (Desaprobado) y 1 (Aprobado)]
data['aprobado'] = (data['promedio'] >= 10.5).astype(int)Si el promedio es mayor o iguala a 10.5 se devuelve verdadero, el cual representará aprobado, caso contrario será desaprobado. Mediante el método astype(int) de Pandas convertimos estos valores Booleanos a Enteros.
Crearemos dos variables para recoger los datos a entrenar, la variable data_edad y la variable data_aprobado
data_edad = data[['edad']]
data_aprobado = data['aprobado']Ahora vamos a importar la clase LogisticRegression desde el módulo sklearn.linear_model.
from sklearn.linear_model import LogisticRegressionSklearn: Esto se refiere a la biblioteca scikit-learn, una biblioteca popular de aprendizaje automático (machine learning) en Python.
linear_model: Este es un módulo dentro de scikit-learn que contiene varios modelos lineales, incluyendo la regresión logística.
Estoy utilizando esta línea para importar la clase LogisticRegression para que posteriormente puedas crear una instancia de ella model = LogisticRegression() y usarla para predecir la aprobación de los estudiantes en función de su edad.
PASO 7
Instanciamos model para luego entrenarla mediante el metodo fit() pasándole como argumentos data_edad y data_aprobado
model = LogisticRegression()
model.fit(data_edad, data_aprobado)Nuestro modelo se entrenará buscando la relación entre estos dos argumentos, es decir, ajustar el modelo a los datos de entrenamiento para aprender la relación entre las características (en este caso, la edad) y la variable objetiva (aprobado o no aprobado).
Bien, ya casi terminamos, ahora vamos a construir una validación de mínima y máxima edad para aterrizar la predicción basándonos en los datos históricos. Obviamente necesario, pues un estudiante de 2 años no podría ser evaluado en este escenario.
edad_minima = data['edad'].min()
edad_maxima = data['edad'].max()Simplemente, buscamos el mínimo y máximo valor de la columna edad de nuestro DataFrame, mediante los métodos min() y max()

PASO 8 – La Magia
Ya tenemos la instancia model entrenada, ahora vamos a pasarle el dato a evaluar «para nuestro caso la edad del nuevo estudiante», de esta forma nuestro modelo nos devolverá la posible nota basándose en la data histórica que ya ha evaluado.
Creamos una nueva variable llamada nuevo_estudiante para recoger un nuevo DataFrame de un solo registro (la edad del nuevo estudiante) que evaluaremos próximamente. El método usado es DataFrame() de Pandas
Luego pasamos una simple condicional de tipo if para descartar los valores de edad que no estén dentro del rango de nuestra Data Set.
Finalmente, si la edad a evaluar esta dentro del rango, lo pasamos por la instancia model entrenada previamente mediante el método predict_proba() de LogisticRegression, pasando como argumento el DataFrame nuevo llamado nuevo_estudiante.
Recordar que el DataFrame nuevo_estudiante solo tiene un registro, pues en este caso así se ha planteado el ejercicio, por tal motivo solo tendremos un registro a evaluar, con [0] recogemos el primer resultado devuelto.
Las líneas finales son simplemente presentación del resultado con porcentaje de aprobación mediante programación tradicional.
edad_nueva = 15
nuevo_estudiante = pd.DataFrame({'edad': [edad_nueva]})
# Donde 'edad_nueva' es la edad del nuevo estudiante
if edad_nueva < edad_minima or edad_nueva > edad_maxima:
print("La edad del estudiante está fuera del rango del dataset.")
print("No se puede calcular la probabilidad de aprobar.")
else:
probabilidad = model.predict_proba(nuevo_estudiante)[0]
print(f"Probabilidad de aprobado: {probabilidad[1]*100:.2f}%")
print(f"Probabilidad de desaprobado: {probabilidad[0]*100:.2f}%")
PASO 9
Vuelve a repasar toda esta guía y juega un poco con este ejercicio….