Red Neuronal Artificial con Capas Intermedias
En este apunte “Crea tu Primera Red Neuronal Artificial” desarrollamos un modelo sencillo para calcular el perímetro de un círculo.
Se usaron como set de datos solamente:
| Entrada en cm | 3 | 4 | 5 | 8 | 10 | 12 | 15 |
| Salida en cm | 18.85 | 25.13 | 31.42 | 50.27 | 62.83 | 75.4 | 94.25 |
Son pocos datos pero los suficientes para predecir, por ejemplo, cuál el perímetro de un círculo con radio = 22
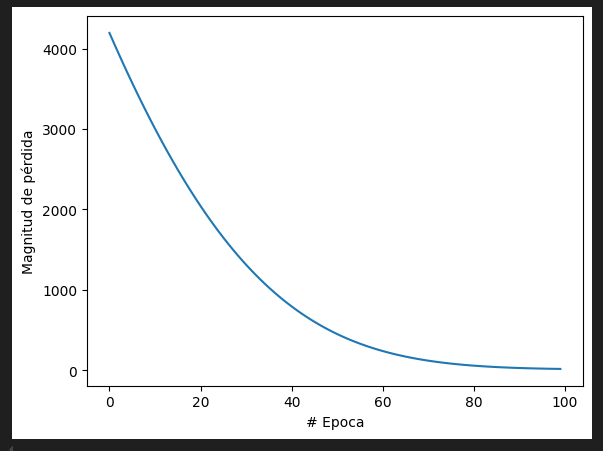
Con solo 2 neuronas, sin capas intermedias y 100 épocas obtenemos la siguiente curva de aprendizaje y resultado.
¿Bastante cerca verdad?
Considerando que el perímetro de un círculo de radio = 22 cm es 138.23 cm, tenemos un nivel de confianza de 94.07%
Bien, pero consultemos ahora un radio = 150 cm a nuestro modelo matemático ya entrenado:
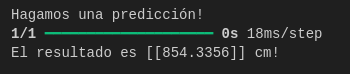
Y considerando que el perímetro de un círculo de radio = 150 cm es 942.48 cm, tenemos un nivel de confianza de 90.6 %
Con esto queda claro que mientras más alejemos la variable a consultar con respecto a los datos históricos de entrenamiento, menos nivel de confianza obtenemos en la predicción.
¿Qué podemos hacer?
Existen muchos métodos para mejorar la asertividad de nuestro modelo de red neuronal artificial, por ejemplo podríamos aumentar el set de datos o dataframe de entrenamiento, también podríamos aumentar el número de épocas y jugar con el factor de ajuste del algoritmo Adam, sin embargo, dado que solo tenemos 2 neuronas es poco probable que nuestro modelo tenga grandes mejoras, motivo por el cual llegó el momento de aumentar el número de neuronas.
Para aumentar el número de neuronas, insertaremos capas intermedias y volveremos a entrenar nuestro modelo.
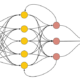
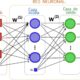
Imagen de nuestra red neuronal antes de la mejora
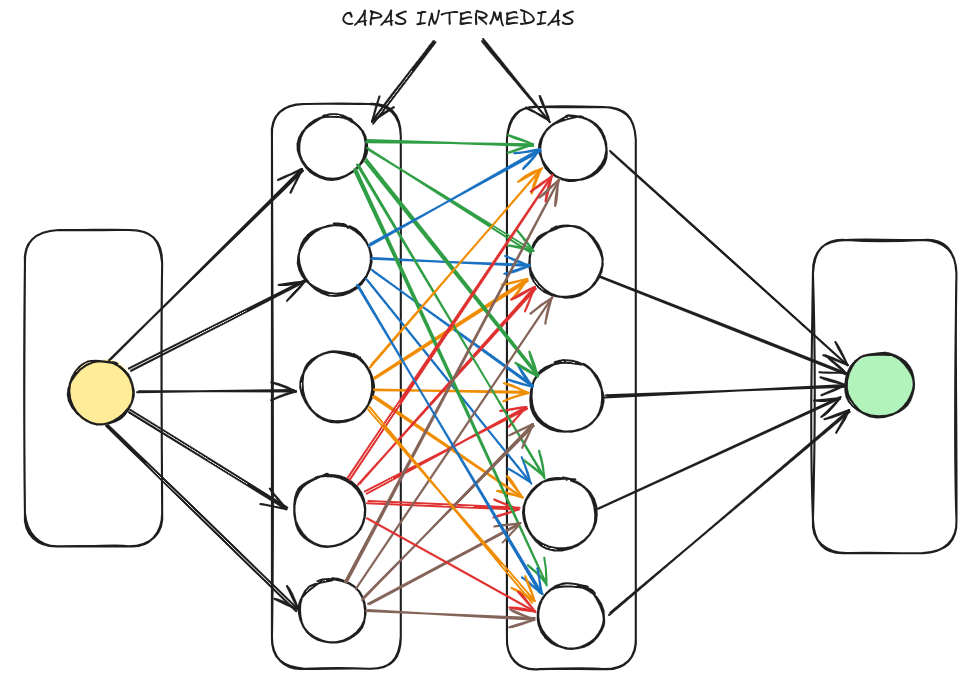
Imagen de nuestra red neuronal agregando 2 capas intermedias y 5 neuronas adicionales por capa.
Vamos a programarlo…
Importamos las librerías necesarias:
import tensorflow as tf
import numpy as npArmamos nuestro arreglo de datos de entrenamiento.
entradacm = np.array([3, 4, 5, 8, 10, 12, 15], dtype=float)
salidacm2 = np.array([18.85, 25.13, 31.42, 50.27, 62.83, 75.4, 94.25], dtype=float)Creamos un modelo de red neuronal con tres capas densas en TensorFlow/Keras
oculta1 = tf.keras.layers.Dense(units=5, input_shape=[1])
oculta2 = tf.keras.layers.Dense(units=5)
salida = tf.keras.layers.Dense(units=1)
modelo = tf.keras.Sequential([oculta1, oculta2, salida])tf.keras.layers.Dense: Estamos creando una capa densa, que es un tipo de capa fundamental en las redes neuronales artificiales. Las capas densas conectan todas las neuronas de una capa con todas las neuronas de la capa siguiente.
units=5: Este argumento especifica que la capa tendrá cinco neuronas en la salida. Esto significa que la capa producirá cinco valores como resultado.
input_shape=[1]: Aquí se define la forma de la entrada a esta capa. En este caso, la entrada será un solo valor (un escalar)
tf.keras.Sequential: Esta función se utiliza para crear un modelo secuencial en Keras. Un modelo secuencial es una pila lineal de capas.
[oculta1, oculta2, salida]: Dentro de los corchetes se coloca una lista de las capas que componen el modelo. En este caso, tenemos tres capas: la primera oculta, la segunda oculta y la de salida.
Configuramos el modelo para utilizar el optimizador Adam con una tasa de aprendizaje inicial de 0.1
modelo.compile(
optimizer=tf.keras.optimizers.Adam(0.1),
loss='mean_squared_error'
)modelo.compile(): Este método se utiliza para configurar el modelo de red neuronal antes de entrenarlo. En él, se especifican los parámetros necesarios para el proceso de entrenamiento.
tf.keras.optimizers.Adam: Este argumento indica que se utilizará el optimizador Adam para el entrenamiento del modelo. Adam es un algoritmo de optimización adaptativa que ajusta la tasa de aprendizaje durante el entrenamiento para acelerar la convergencia.
0.1: Este valor representa la tasa de aprendizaje inicial del optimizador Adam. La tasa de aprendizaje determina la rapidez con la que el modelo ajusta sus pesos durante el entrenamiento. Una tasa de aprendizaje más alta puede acelerar el entrenamiento, pero también puede hacer que el modelo sea más inestable.
loss: Este argumento especifica la función de pérdida que se utilizará para evaluar el error del modelo durante el entrenamiento. La función de pérdida mide la discrepancia entre las predicciones del modelo y los valores reales.
‘mean_squared_error’: Esta cadena de texto indica que se utilizará el error cuadrático medio (MSE) como función de pérdida.
Entrenamos el modelo mediante el método fit()
print("Comenzando entrenamiento...")
historial = modelo.fit(entradacm, salidacm2, epochs=100)
print("Modelo entrenado!")El argumento epochs = 100 define el número de épocas (ciclos de entrenamiento) a ejecutar.
Dibujamos el rendimiento de entrenamiento
import matplotlib.pyplot as plt
plt.xlabel("# Epoca")
plt.ylabel("Magnitud de pérdida")
plt.plot(historial.history["loss"])Finalmente, consultemos a nuestro modelo entrenado por un radio de 150 cm
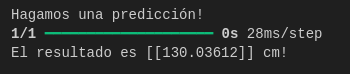
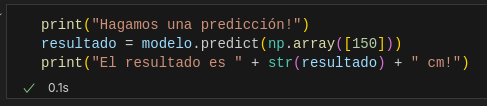
print("Hagamos una predicción!")
resultado = modelo.predict(np.array([150]))
print("El resultado es " + str(resultado) + " cm!")Los resultados:
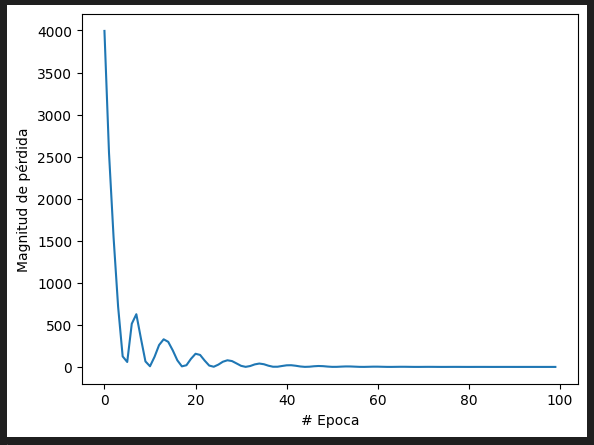
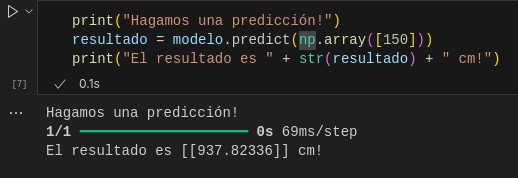
Con los resultados obtenidos podemos ver que nuestro modelo con 2 capas intermedias y más neuronas hemos obtenido un mejor resultado.
El perímetro de un círculo de radio = 150 cm es 942.48 cm y nuestro modelo ha dado como respuesta 937.82 cm obteniendo así un nivel de confianza de 99.5 %, mucho mejor que nuestra red de solo 2 neuronas.